一个活的第二大脑 连接一切 你思考的工具
你的 AI 工具、你的笔记、以及未来的一切——统一在一张知识图谱中。开源、本地优先。
你的记忆正在碎片化
Claude 记得你喜欢简洁的代码,但 Cursor 毫不知情。你花了一周在笔记里整理设计思路,但下次和 AI 讨论时,它一无所知。每个工具都在悄悄积累对你的理解,却没有任何东西将它们连接起来。
记忆孤岛
每个 AI 工具各有各的记忆,彼此互不相通。
扁平事实列表
现有的 AI 记忆只是罗列事实,不会关联、不会发现、不会演化。
噪声增长
随着记忆堆积,数据变得冗余,越来越难检索。
更深层的问题不是数据同步,而是认知碎片化。
第二大脑应有的样子
不只是存储——是你认知系统的真正延伸。
统一记忆
所有 AI 工具和笔记共享一张知识图谱。不同 AI 的对话、不同应用的笔记——不再是信息孤岛,而是交织共生。
完整画像
每次对话开始时,你的 AI 都会收到从所有历史交互中提炼的画像——你是谁、怎么思考、关注什么。
图导航式检索
沿着记忆之间的链接导航——从一个决策到背后的讨论,再到后续引发的变更。按需探索,而非关键词猜测。
活的代谢
记忆自然衰减、发散扫描发现隐藏关联、重要模式结晶为洞察——就像生物记忆一样。
笔记同步
从 Obsidian、Logseq、Apple Notes 一键导入。笔记和 AI 对话在同一张图谱中交叉授粉。
100% 本地
所有数据存储在本机的 SQLite 文件中,随时可导出为 Markdown。无需云端,无供应商锁定。支持 Ollama 全本地运行。
三个认知操作
这不是 CRUD。它模拟生物记忆的工作方式——通过 MCP 协议。
加载记忆上下文
每次对话开始时
就像打开记忆地图——你的 AI 收到完整的画像和关键记忆。
导航和检索
需要历史上下文时
不只是搜索——AI 沿着记忆之间的链接导航,按需探索图谱。每次检索都会巩固被访问的记忆。
存储新信息
产生值得记住的内容时
不只是保存——传入的信息被分解、连接、编织到已有的知识网络中。
后台代谢
就像大脑在睡眠时整理记忆——TideMind 持续维护知识图谱。
自然衰减
不活跃的记忆逐渐淡化。枢纽节点受到保护。
发散扫描
发现未连接的想法之间隐藏的关联。
结晶涌现
重要模式结晶为提炼后的洞察。
有何不同
| 典型 AI 记忆 | TideMind | |
|---|---|---|
| 画像 | 没有画像,或局限于单个 AI 内 | 从所有数据构建完整画像,在每次对话开始时提供 |
| 存储 | 扁平的事实列表 | 记忆在多个维度上动态演化的知识图谱 |
| 检索 | 关键词/向量 top-K | 从最相关的记忆出发,沿链接探索,按需扩展 |
| 涌现 | 存储的记忆保持冻结 | 一个能产生新认知的活系统 |
| 数据 | 云端 / 供应商锁定 | 本地 SQLite 文件,随时导出为 Markdown |
看看你的大脑在想什么
桌面客户端是一个观察工具——观察你的外脑正在发现什么、遗忘什么。你的主界面是你正在使用的任何 AI 工具。
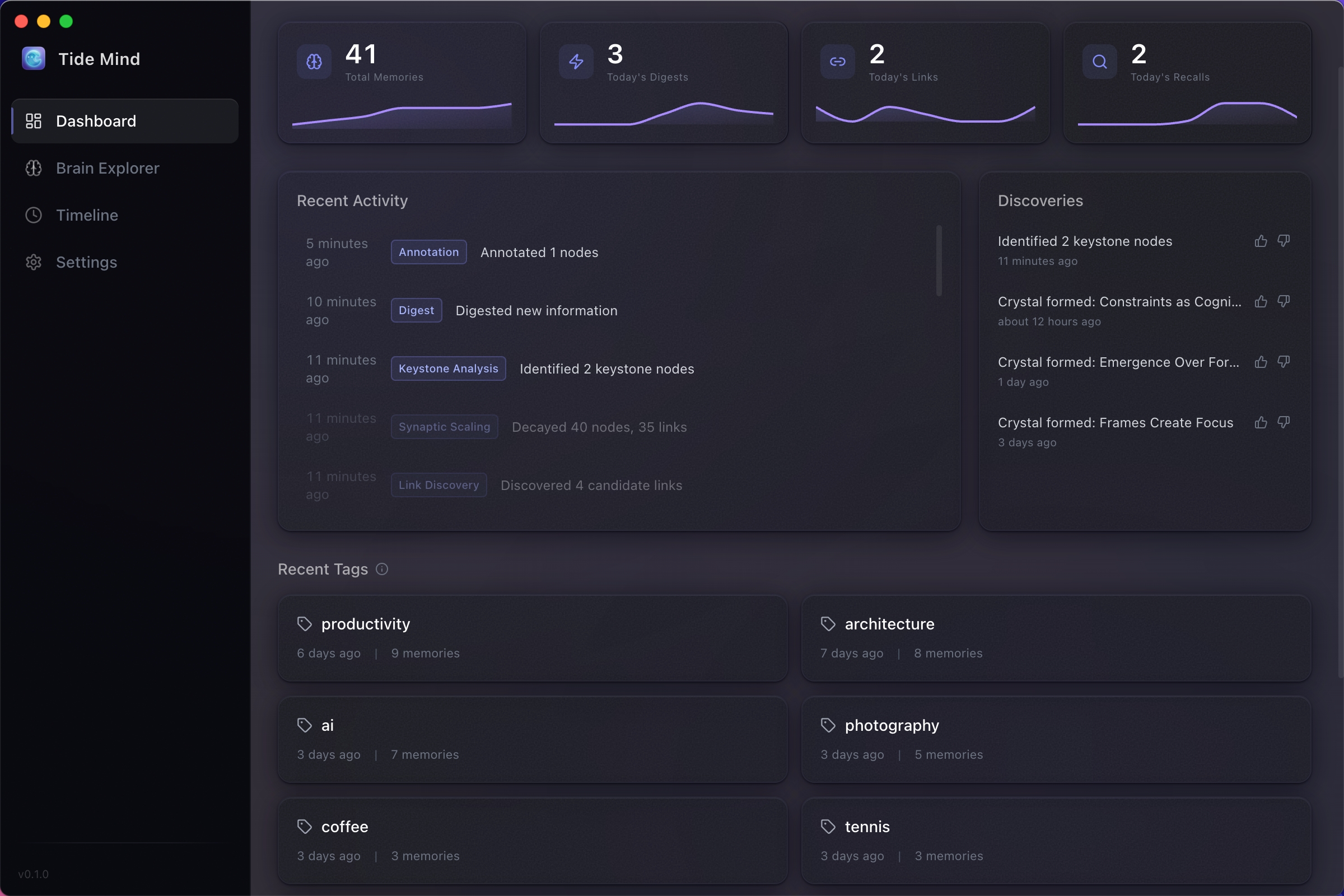
仪表盘
第二大脑的实时脉搏——指标、活动流、结晶发现。
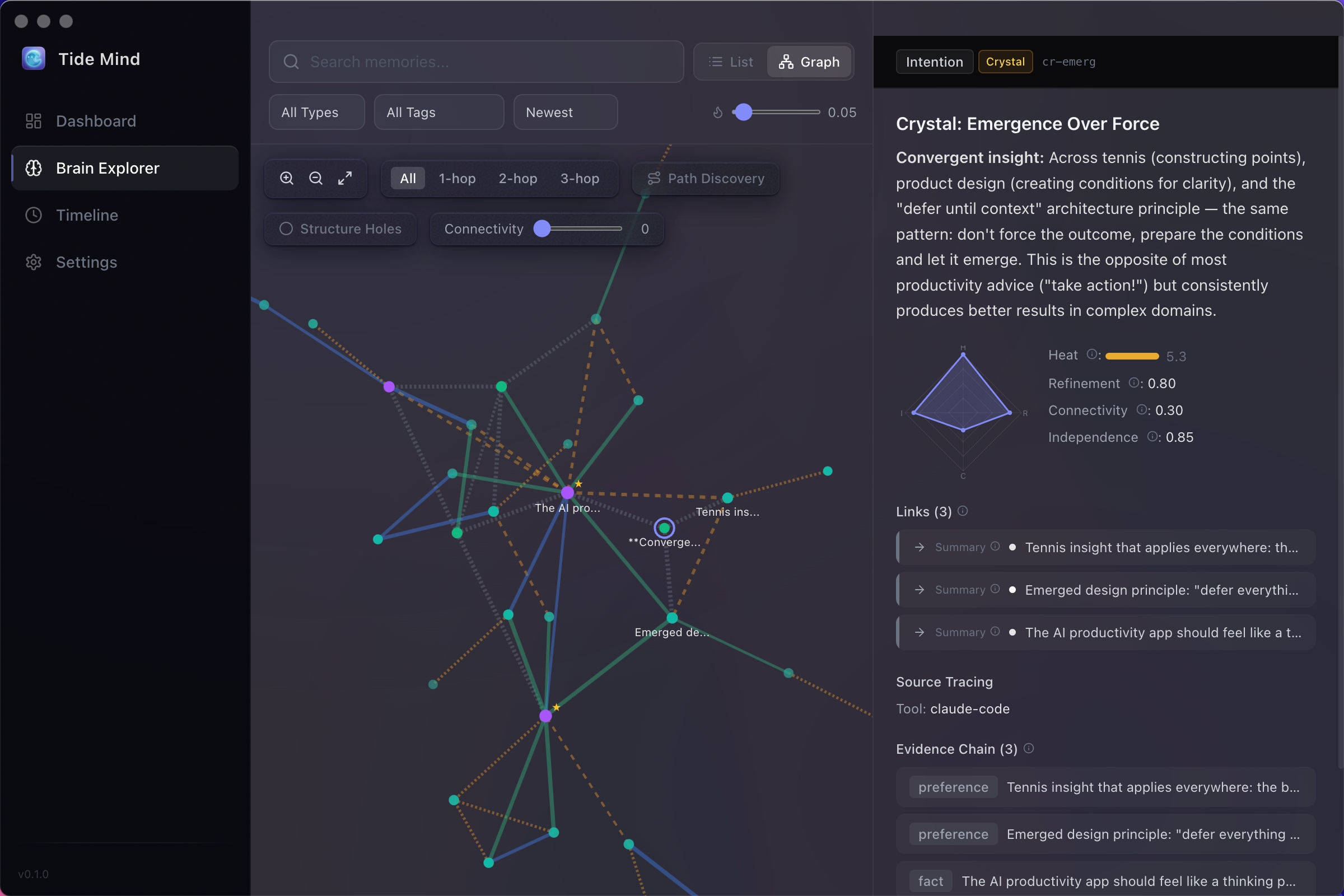
大脑探索器
在交互式图谱中可视化你的记忆如何跨领域连接。
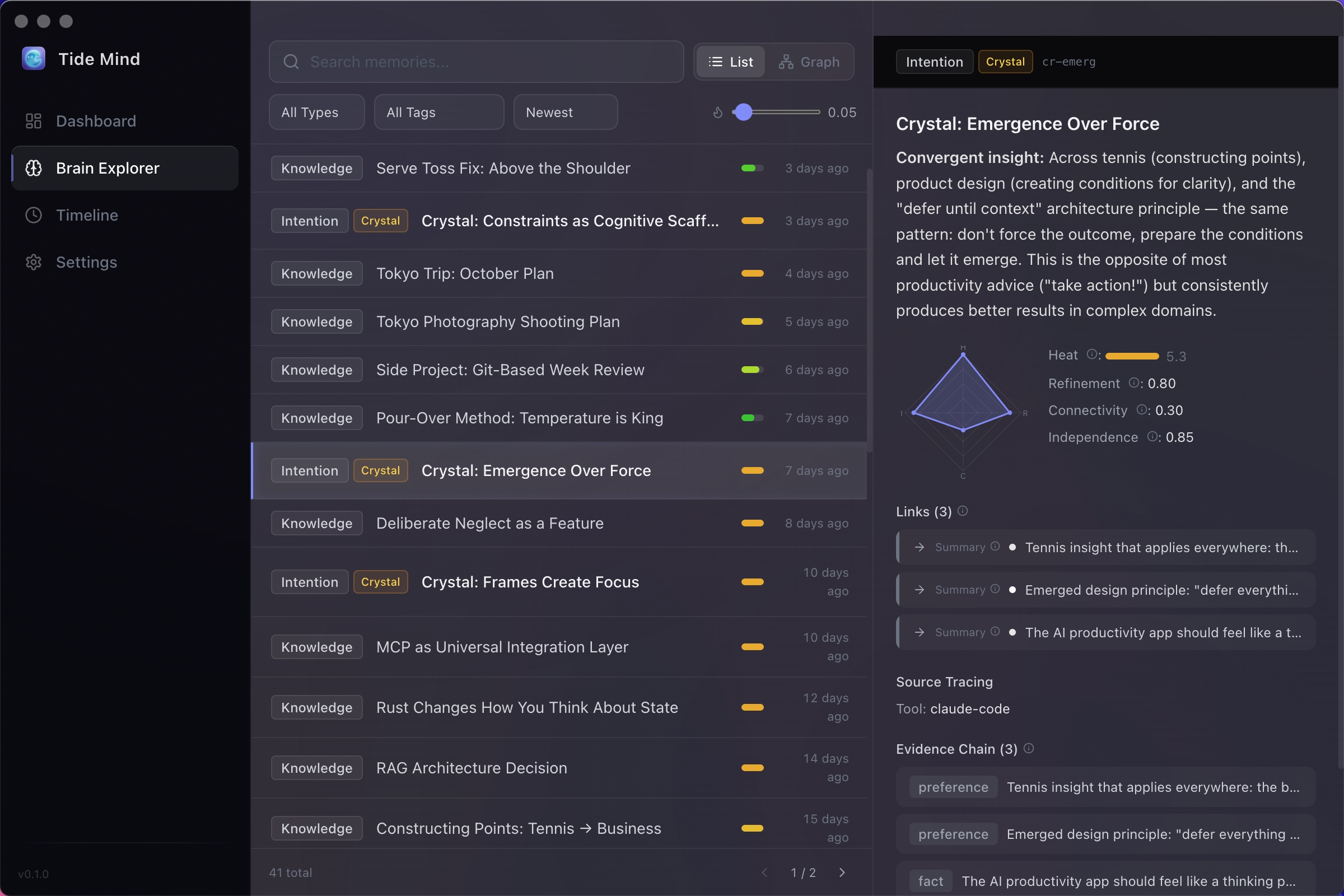
记忆详情
四维度成熟度模型、证据链和关联节点。
与你的工具
通过 MCP 协议连接——一次配置,无需改变习惯。
AI 工具
笔记系统
常见问题
关于 TideMind 的常见疑问——它是什么、怎么用、有何不同。